FinOps for Kafka: How to optimize your Kafka costs
- Kim-Carolin Lindner & Sahand Zarrinkoub

- Aug 14, 2025
- 8 min read
Updated: Sep 10, 2025
Introduction
Apache Kafka has become a foundational component of modern data architectures, powering everything from real-time analytics and event-driven systems to data pipelines and microservices communication. But while Kafka has many capabilities, it is also resource-intensive-especially when deployed at scale. Whether running self-managed clusters or leveraging managed services like Confluent Cloud, Amazon MSK, or Azure Event Hubs, organizations often find themselves grappling with rising infrastructure costs and unpredictable scaling demands.
This is where FinOps-the intersection of Finance and DevOps-becomes relevant. By applying FinOps principles and capabilities, companies can bring financial accountability to Kafka deployments, improve cost transparency, and make smarter trade-offs between speed, quality, and cost.
In this post, we explore how FinOps practices can be applied to Apache Kafka across various deployment models. We'll walk through common architecture options, cost optimization levers, and concrete steps for aligning Kafka usage with business value-all while maintaining performance and scalability.
What is Apache Kafka?
Apache Kafka is a distributed event-streaming platform built to handle real-time data at scale. Originally developed by LinkedIn and now an open-source project maintained by the Apache Software Foundation, Kafka enables organizations to collect, process, store, and integrate data streams across various sources and systems with high throughput and low latency.
Commonly, Kafka is used for scenarios like user activity tracking, real-time analytics, metrics collection, log aggregation, stream processing, and publish-subscribe messaging. It models each event as a key-value pair-where the key might be an identifier like a user ID or order number, and the value could be anything from a simple message to a complex application object. These events can be serialized using formats such as JSON, Avro, or Protobuf.
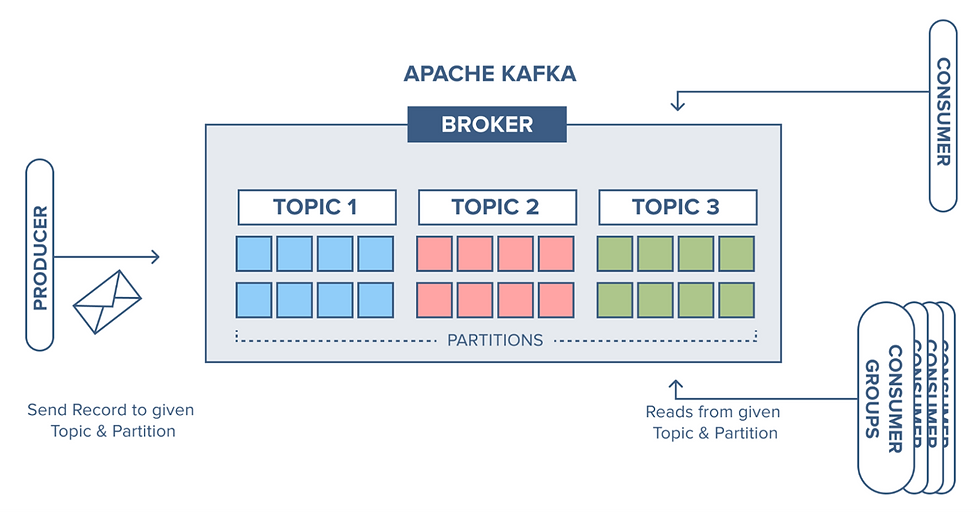
Kafka's architecture (see Figure 1) is designed for scalability, resilience, and performance. Its core components include:
Topics: The primary unit of data organization, acting like a log of immutable events.
Partitions: Each topic is split into partitions to distribute load across multiple nodes. The partition is the primary unit of parallelization in Kafka and Kafka guarantees FIFO (First In First Out) ordering within each partition.
Brokers: Kafka servers that store and serve data and metadata; they host partitions and manage read/write requests.
Replication: Partitions are distributed redundantly across brokers, with one acting as the leader and others as followers.
Producers and Consumers: Client applications outside of the cluster that write data to and read data from Kafka topics.
Kafka can be deployed in self-managed environments or accessed through managed services like Amazon MSK or Confluent Cloud. In either case, adequate resource allocation is essential in order to provide sufficient performance and manage costs.
What is FinOps?
FinOps brings financial accountability and cross-functional collaboration to cloud spending, helping engineering, finance, and business teams work together to make informed, cost-efficient decisions. It is an operational framework that enables organizations to extract maximum business value from the cloud by helping teams own their usage while making trade-offs between speed, cost, and quality.
FinOps includes four primary domains that represent the core outcomes of a FinOps practice:
Understand Usage & Cost
Quantify Business Value
Optimize Usage & Cost
Manage the FinOps Practice
These domains are supported by a set of capabilities that “describe how to achieve them”.

The Relevance of FinOps for Apache Kafka
Apache Kafka, while powerful and flexible, is also resource-intensive, especially when deployed at scale in user-managed environments. Brokers continuously consume compute, memory, disk, and network resources, whether they’re under load or idling. Without careful planning and active management, Kafka deployments can quickly become expensive. This is where FinOps plays a crucial role, helping organizations strike the right balance between performance and cost efficiency.
How FinOps Practice Applies to Kafka
Visibility: Understand Resource Usage and Cost Drivers
Kafka clusters consist of brokers, ZooKeeper nodes (unless you’re using KRaft), storage, and network traffic-all of which generate infrastructure costs. Gaining visibility into these components is a foundational FinOps practice:
Monitor per-broker resource utilization (CPU, memory, disk I/O).
Track partition counts and replication factors-both drivers of storage and compute costs.
Capture metrics like producer throughput, consumer lag, and message retention to understand usage patterns.
In managed services, monitor billing by resource type (e.g., in Confluent Cloud: GB-ingested, GB-stored, GB-ejected).
Optimization: Right-Size and Tune Kafka Resources
Optimizing Kafka costs means aligning the cluster’s configuration with actual demand:
Reduce over-provisioning: Scale down idle brokers or adjust instance types.
Optimize retention policies: Avoid retaining messages longer than necessary.
Balance partitions wisely: Over-partitioning increases metadata overhead; under-partitioning can reduce throughput.
Tune replication factors: While needed for fault tolerance, excessive replication increases storage and network costs.
In managed services, optimization also includes selecting appropriate service tiers or ingest plans and setting limits on throughput and storage.
Accountability: Allocate and Showback Costs
Kafka often serves multiple teams or use-cases within an organization, making cost attribution essential. FinOps practices can support this:
Use consistent topic naming conventions and tag infrastructure components like clusters, EC2 instances hosting Kafka brokers, or storage volumes to facilitate cost allocation.
Utilize platforms that support topic-level tagging like BytePlus to directly assign tags such as team name, environment, or project to each topic for further insights.
Partition usage tracking to reveal which teams generate the most load or data volume.
Showback reports that help engineering teams see the cost impact of their usage and drive more cost-aware decisions.
Automation & Governance
Cost optimization should be proactive and sustainable, not just manual:
Automate scaling policies (where possible).
Implement data retention governance to prevent unbounded topic growth.
Set up alerts for anomalous usage or unexpected cost spikes.
By embedding FinOps practices into the lifecycle of Kafka infrastructure from provisioning to monitoring and continuous optimization-organizations can ensure Kafka’s power doesn’t come at the expense of financial efficiency.
Different Deployment Types for Running Apache Kafka
Before diving into cost optimization strategies, it's essential to understand the different ways Kafka can be deployed-each with its own trade-offs in terms of operational complexity, flexibility, and cost transparency.
Serverless Kafka
In a serverless deployment, the Kafka infrastructure is entirely abstracted away. The provider manages scalability, high availability, maintenance, and security. This is the most hands-off option and typically follows a usage-based pricing model.
Key Characteristics:
No need to manage infrastructure, brokers, or scaling logic.
You pay per use-costs are typically based on storage (GB), data ingress/egress, and partitions.
Great for unpredictable workloads or teams looking to reduce operational overhead.
Examples
Confluent Cloud: Offers true usage-based pricing with no minimums.
Amazon MSK Serverless: Bills per cluster-hour, partition-hour, storage, and data throughput.
Azure Event Hubs for Kafka: Enables Kafka client compatibility with Event Hubs in a fully managed, serverless environment.
2. Managed Kafka Services
Managed Kafka services offer more control than serverless deployments but still handle major aspects like provisioning, lifecycle management, patching, and monitoring. Users are typically responsible for choosing instance sizes, scaling settings, and some configuration details.
Key Characteristics:
Offers some configurability without the full burden of self-management.
Pricing is resource-based: compute (vCPU/memory), storage (GB-month), and network usage.
Greater transparency and control than serverless but requires some knowledge about operating a Kafka cluster.
Examples:
Confluent Cloud (Dedicated cluster): Dedicated infrastructure, suitable for critical workloads or those requiring private networking. Scaling is manual, as opposed to the other cluster types offered by Confluent Cloud.
Amazon MSK Provisioned:
Choose between standard and express brokers (with different scaling and cost patterns).
Pay for instance-hours, storage, and optional data throughput provisioning.
Add-on features include MSK Connect (Kafka Connect) and MSK Replicator.
Azure Event Hubs (Dedicated Tier): Offers more capacity and features than the serverless version, including Kafka protocol support and SLAs.
Self-Hosted Kafka
In self-managed deployments, users are fully responsible for provisioning and maintaining the entire Kafka stack—from broker nodes and ZooKeeper (or KRaft) to monitoring, scaling, and backups. This approach is often chosen for very small (cost-sensitive) or very large (performance-tuned) deployments where fine-grained control is needed.
Key Characteristics:
Full control over infrastructure and configurations.
High operational burden (setup, patching, scaling, securing).
Potentially lower total cost at high scale but requires significant Kafka expertise.
Examples:
AWS EC2 / EKS-based Kafka: Kafka brokers (e.g. using Confluent Platform software) run on EC2 instances or as pods in EKS; EBS volumes are attached for storage.
Azure VM or AKS deployments: Kafka runs on virtual machines or Kubernetes, integrated with Azure storage and monitoring.
On-premises: Still common in regulated industries or hybrid cloud architectures.
Each deployment model affects cost visibility and control differently, which is where FinOps plays a critical role. In the next section, we'll dive into how to optimize Kafka costs-regardless of how it’s deployed-by applying FinOps strategies like resource tuning, right-sizing, and usage-based chargeback.
Cost Optimization Strategies for Kafka Deployments
While Kafka is a powerful event-streaming platform, it can also drive up cloud expenses. Whether you run Kafka serverless, hosted, or self-managed, there are several optimization levers that FinOps teams and platform owners can pull to improve efficiency and reduce spend.
Commitment-Based Discounts (Where Available)
For self-managed deployments, standard commitment-based options for Compute, such as EC2 Reserved Instances (RIs) and Compute Savings Plans (SPs) are available.
For managed Kafka services on AWS and Azure, commitment options are not offered as of today. However, GCP offers Committed Use Discounts (CUDs) for its Managed Kafka Service allowing up to 40% savings when committing to usage for one or three years.
Confluent Cloud, as a serverless example, offers General Purpose Clusters, which provide different pricing tiers that save up to 60% on throughput-related costs, dependent on the monthly commitment.
Other special offers bundled into enterprise contracts with Kafka vendors.
Rightsizing and Scaling Smarter
Kafka Clusters are designed for horizontal scaling. In self-managed and managed environments, scaling is the responsibility of the user. Scaling should be done cautiously and ideally planned for predictable spikes or when load is expected to increase for an extended amount of time. Kafka brokers don't scale like stateless apps-scaling out requires partition reassignment and leader re-election for each new node, leading to significant I/O and latency penalties. When using serverless services such as Confluent Cloud (for General Purpose Clusters) and Amazon MSK Serverless, the problem of scaling is handled by the service provider.
Storage and Retention Optimization Regardless of deployment strategy, storage often accounts for a large share of Kafka costs, especially when messages are retained for long periods or with high replication factors.
Tiered Storage: In self-hosted or managed Kafka deployments, offload older Kafka segments to cheaper object storage (e.g. by using, Confluent’s Tiered Storage Amazon MSK Tiered Storage or Strimzi’s Tiered Storage). This allows long retention at a lower price point. With the acquisition of WarpStream, Confluent has added a Kafka-compatible streaming service that is object storage-native, eliminating the need for disk storage altogether, which is a suitable low-cost alternative for high-latency use cases with large data volumes.
Tune Retention Policies: Reduce the log.retention.hours or log.retention.bytes settings (which control how much logs are retained), especially in test and dev environments.
Compression: Enable producer compression to reduce payloads and improve network efficiency.
Avoiding Hidden Cost Traps Misconfigured Kafka setups can quietly inflate your bill:
Cross-AZ or cross-cloud traffic can lead to big networking costs, especially in AWS. For self-hosted or managed deployments, ensure that producers, consumers, and brokers reside in the same Availability Zone when possible.
Storage: Unlike CPU or memory, storage in cloud Kafka services (like MSK or Confluent Cloud) is often billed per GB-month. Always align disk size with actual usage. For deployments where you configure the disk size yourself, make sure not to over-provision it.
Excessive replication: Replication is critical for durability, but defaulting to a replication factor of 3 may not be necessary for all topics. Make sure that replication is used according to the actual need for durability.
Optimize payloads: Avoid verbose formats like JSON when possible and educate teams on efficient serialization.
Operational and Governance Optimizations
Streamlining operational overhead can also pay off, for example by reducing network traffic due to metadata calls:
Audit and clean up inactive topics, partitions, and consumer groups regularly.
Restrict topic creation and enforce quotas to avoid abuse or over-provisioning.
Chargeback and Accountability
Attributing Kafka usage to individual teams or services is key to building cost awareness and accountability. Chargeback not only promotes transparency, but also incentivizes teams to reduce waste, right-size their workloads, and adopt more efficient usage patterns-all aligned with FinOps principles of accountability and cost ownership.
Topic Tagging: Some managed Kafka platforms like BytePlus support topic-level tagging, which can directly link usage to cost centers. In platforms where native tagging isn't available, implement structured naming conventions or external metadata systems to achieve similar granularity.
Encourage Cost Accountability: Exposing teams to their Kafka-related costs encourages better design choices, such as reusing topics, reducing retention, or avoiding over-replication-ultimately driving more cost-efficient Kafka usage.
By combining platform-native optimization tools with FinOps best practices like usage monitoring, chargeback, and lifecycle governance, Kafka cost control becomes not just possible, but scalable. A proactive FinOps approach allows teams to balance performance and cost efficiently.
Bringing It All Together: Kafka Cost Optimization Through a FinOps Lens
Effectively managing the cost of Apache Kafka-especially at scale-requires more than just technical fine-tuning. It demands a structured, cross-functional approach to cloud financial management. In this blogpost, we discussed how FinOps provides structure and discipline for your Kafka environment: by making cloud spending visible, optimization actionable, and accountability shared. Whether you're operating Kafka in a serverless, managed, or self-managed environment, FinOps helps teams translate engineering choices into financial outcomes. Through practices like resource rightsizing, retention tuning, chargeback reporting, and governance automation, Kafka can deliver high performance and cost efficiency. Ultimately, Kafka cost optimization is not a one-time task – it’s an ongoing capability. And with FinOps embedded into your platform strategy, it becomes a sustainable one.



Comments